

- Introduzione
È difficile riassumere in poche pagine la profonda rivoluzione che stiamo vivendo senza quasi accorgercene. Una rivoluzione che nasce dall’unione di tecnologie che fino a una decina d’anni fa esistevano solo nei laboratori di ricerca e che oggi permeano ogni aspetto della nostra vita: i cosiddetti “Big Data”, l’intelligenza artificiale (IA) e le bio-nanotecnologie. Tre tecnologie che, se ben gestite indirizzate e disciplinate potrebbero realmente condurre a quella transizione tra Homo Sapiens Sapiens e Homo Deus anticipata dai transumanisti per un futuro relativamente vicino. Un futuro che promette la sconfitta del cancro e della quasi totalità delle malattie, una vita attiva molto più lunga di quella attuale, un accesso illimitato all’informazione, un benessere molto meglio distribuito e un migliore controllo dell’ambiente. Questa stessa triade fa però nascere dilemmi etici, legali e filosofici che non hanno precedenti nella storia umana e che fanno impallidire persino quelli indotti dall’avvento delle tecnologie nucleari. Una volta di più, il genere umano deve confrontarsi con la mitologica figura di Giano: da un lato la promessa di sviluppi straordinari negli ambiti più disparati, e dall’altro scenari angoscianti e orwelliani che prevedono la perdita delle libertà individuali e la possibile distruzione della civiltà come la intendiamo oggi.
L’analogia con la scoperta del nucleare regge però solo fino a un certo punto: gli aspetti negativi e la potenza distruttiva del nucleare erano infatti evidenti a tutti. L’esplosione della bomba di Hiroshima segnò una cesura netta nella storia e una chiara presa di coscienza di quali erano le possibili conseguenze di un cattivo uso del nucleare[1]. Almeno in teoria, se lo si fosse voluto, il nucleare avrebbe potuto essere proibito mentre ciò che sta accadendo oggi, sebbene potenzialmente ancor più distruttivo, è un processo che, una volta innescato, non si potrà più fermare. Non esisteranno interruttori da spegnere, né leggi che potranno disciplinare gli eventuali abusi. Si tratta, infatti, di una convergenza di sviluppi tecnologici che, nel momento in cui i vari trefoli si incontreranno a formare un canapo, cambieranno il mondo in modo imprevedibile e soprattutto ineluttabile[2]. In altre parole, se ciò che si troverà dall’altro lato del canapo non ci piacerà, non potremo più tornare indietro e dovremo, se potremo, imparare a coesistere con esso. Anche il solo pensare di potere arrestare questo processo sarebbe infatti stupido e velleitario. Gli interessi economici, le modifiche sociali già avvenute, la nostra sempre maggiore interconnessione e la dipendenza da questo tipo di tecnologie, rendono infatti impensabile il tornare indietro. I treni, i viaggi aerei, la gestione del traffico, il traffico marittimo e il commercio, la produzione di energia, si fermerebbero. Mai come in questo caso, quindi, il genere umano deve riuscire a fare una cosa che raramente ha saputo fare: controllare un processo mentre è ancora in corso e non limitarsi a cercare di riparare i danni una volta che questi si sono già verificati. Per usare una metafora, ormai la nave è in viaggio ed è già lontana dalle terre emerse e sta solo a noi evitare il naufragio e cercare di raggiungere le ricchezze del Nuovo Mondo. Ed è per questo motivo che, a uno scienziato che lavora nel settore dei Big Data, appare ancora più incomprensibile e per certi versi spaventoso, il silenzio pressoché totale della politica e delle scienze giuridiche su ciò che sta accadendo. Anche la stessa filosofia, che nei momenti più bui della nostra storia è stata un faro – a volte impietoso e cinico – che, illuminando il presente ha permesso di scorgere porti sicuri verso cui cercare di indirizzare la rotta, sembra ignorare il problema. Una considerazione è però necessaria. In alcuni paragrafi ho ritenuto indispensabile non omettere alcuni passaggi forse troppo tecnici ma, a mio parere, per comprendere a fondo le implicazioni di una nuova tecnologia o di una nuova disciplina scientifica non ci si deve mai dimenticare che di scienza e tecnologia si tratta.
1. 1 I Big data
Negli ultimi dieci anni, l’avvento di nuove tecnologie nel campo dei sensori, delle tecnologie informatiche e delle reti di comunicazione ha profondamente cambiato il mondo in cui viviamo, stravolgendo antiche prassi e convenzioni. Oggi viviamo in un mondo dove tutto è informatizzato: le transazioni economiche, le diagnosi mediche e le terapie, persino le relazioni interpersonali che oggi avvengono sempre più attraverso i “social” (Facebook, Twitter, VK, Whatsapp, etc.). Se a ciò si aggiungono l’avvento della domotica, il remote sensing, etc.. è facile intuire le conseguenze immediate.
La vita di ognuno di noi lascia una sorta di “scia elettronica” in cui una stringa di informazioni codificate riassume gusti, storia medica, orientamento sessuale, politico e religioso, abitudini di vita e di acquisto, storia finanziaria, ecc. Occorre poi aggiungere i miliardi di dati che ogni anno vengono raccolti da miriadi di sensori che misurano gli aspetti più disparati di tutto ciò che ci circonda: dalle condizioni meteo e atmosferiche, al grado di umidità di piccolissimi appezzamenti di terreno, all’occupazione dei parcheggi, al flusso dei migranti, alle immagini raccolte dalla fitta rete di telecamere che ormai monitora in continuo i centri urbani e non solo. Tutti questi sensori sono connessi – in un modo o nell’altro – con la rete (la cosiddetta “Internet of the Things”, “Internet delle Cose”) e il continuo flusso di dati che essi producono viene in gran parte raccolto e archiviato da quelli che chiameremo “Big Data Provider” (BDP). Proiezioni conservative stimano in 40 Zettabyte[3] i dati che saranno disponibili nell’Internet of Things nel 2020 (una crescita di un fattore oltre 300 rispetto al 2005)[4]. Ma quand’è che una raccolta di dati diventa “Big Data”? La risposta non è chiara e sono in molti ad avere cercato di dare una definizione. La più condivisa si deve all’IBM[5] e caratterizza i big data in termini di quattro variabili (le 4 V dei Big Data)i: volume (dimensioni), varietà, velocità e veridicità (o affidabilità).
Almeno in apparenza, il più ovvio di questi parametri è il volume: quando la quantità di dati supera una certa (arbitraria) soglia, diviene impossibile analizzarli con tecniche tradizionali, basate cioè sull’intervento di operatori umani e occorre ricorrere a tecniche di machine learning (apprendimento automatico). Analogamente, quando la varietà[6] oppure la complessità[7] superano una certa soglia arbitraria[8], di nuovo diviene impossibile un’analisi di tipo tradizionale. La velocità, di fatto si ricollega al problema del volume in quanto se una rete di sensori produce dati a un ritmo troppo elevato per l’operatore umano si rende indispensabile ricorrere a tecniche alternative. Di fatto, tutte queste caratteristiche possono essere ricondotte a un attributo comune: si ha a che fare con “Big Data”, ogni qual volta la potenza di calcolo necessaria a estrarre informazioni da essi diviene ingestibile con tecniche tradizionali e impone un approccio basato su tecniche automatiche in grado di emulare alcuni aspetti dell’operato umano. Tecniche che sono spesso etichettate come Machine Learning, Data Mining, Statistical Pattern Recognition.
Il problema della veridicità è a mio parere trasversale e non ristretto ai soli Big Data: i dati sono spesso incompleti o imprecisi se non addirittura sbagliati. Ovviamente questa incompletezza diviene sempre più difficile da gestire al crescere del volume e della complessità dei dati e si ripercuote inevitabilmente sull’accuratezza dei risultati. Più che una caratteristica definente, la veridicità deve quindi essere considerata un fattore limitante dei Big Data.
1.2 I Big Data Provider
Da poco di più di un decennio e per la prima volta nella storia dell’umanità, i BDP non sono più gli stati o i governi, che in passato controllavano l’accesso ai dati fossero essi contenuti nelle biblioteche o negli archivi (di stato, anagrafici, tributari, giudiziari o sanitari) e ne gestivano l’utilizzo soggetti a un minore (dittature) o maggiore (democrazie) controllo pubblico. Per cecità, per incapacità di adattarsi a un mondo tecnologico in rapidissima evoluzione, per interessi privati più o meno manifesti, gli stati non hanno capito per tempo la portata di ciò che stava accadendo e, nei fatti, hanno delegato il controllo dei dati ai privati. Oggi, i BDP sono pochi, grandi colossi internazionali dai nomi familiari: Apple, Microsoft, Facebook, Amazon, VK; Alibaba, Tencent, Baidu e, primo tra tutti, Google. Stati Uniti e Cina: i due opposti della visione politica uniti da una comune fame di dati. L’Europa, a causa della sua frammentazione e della mancanza di tecnologie specifiche è relegata a un ruolo secondario malgrado non manchino tentativi di recuperare le posizioni perdute. Si veda ad esempio le recenti iniziative del presidente francese Macron per creare un polo di eccellenza nel settore dell’intelligenza artificiale[9]. I BDP sono le più grandi multinazionali del pianeta: i dati hanno un enorme valore associato di cui si parlerà a lungo in seguito. Una società che abbia saputo conquistare un ruolo in questo settore è quindi destinata a vedere il proprio valore aumentare inesorabilmente: gli utenti (spesso definiti dai BDP gli “utili Idioti” del mondo digitale) forniscono altri dati che aumentano il valore della compagnia che può così aumentare i suoi utenti e ottenere ancora più dati e così via. Inoltre, va sottolineato che uno dei principali motori della crescita esplosiva dei BDP è il fatto che essi provvedono linfa vitale a moltissime compagnie che stanno adottando soluzioni data driven. I Big Data sono infatti usati per migliorare le relazioni con clienti già acquisiti e per fidelizzarne di nuovi, per gestire meglio le filiere di produzione e distribuzione, per monitorare in modo automatico il funzionamento di strumentazioni anche complesse, per le cure mediche, per creare nuovi servizi. Moltissime compagnie tradizionali stanno trasformandosi in “data driven companies”. In un recente studio, la International Data Corporation stima la crescita annua dei BDP e delle compagnie a esse collegate intorno al 23.1% annuo con un valore assoluto di 48.6 miliardi di dollari nel 2019.
1.3 La rete
Quando la rete nacque, furono in molti a inneggiare alla decentralizzazione che sembrava insita nella nuova tecnologia e molti credettero che si stava assistendo alla nascita di uno strumento che avrebbe portato all’affermarsi di una nuova forma di democrazia globale. Almeno all’apparenza, chiunque poteva rendere pubbliche le sue opinioni e i prodotti del suo ingegno, e chiunque poteva accedere alle informazioni rese disponibili da chiunque altro. Citando Eugeny Morozov: «i cyber utopisti[10] avevano l’ambizione di costruire delle Nazioni Unite nuove e migliori, e hanno finito per metter su Un Cirque du Soleil in versione digitale...»[11]. In meno di dieci anni la realtà oggettiva (anche se non la percezione collettiva che, come si vedrà tra poco è influenzata dai responsabili della sua trasformazione) del web è radicalmente cambiata. La rete, che avrebbe dovuto aiutare a promuovere i valori della democrazia e della libertà, proprio a causa dei BDP e dei loro interessi commerciali, è divenuta in molti casi uno dei più efficaci strumenti a disposizione di dittatori e demagoghi per alimentare divisioni, per legittimare il consenso su idee retrive, razziste, omofobe.
Per capire come ciò sia stato possibile, è necessaria innanzitutto una premessa. I dati sono numeri, descrizioni di eventi o di oggetti registrate in un codice convenzionale. I dati non interpretati sono sostanzialmente inutili; affinché essi possano essere utilizzati per generare dei feedback, per guidare delle decisioni o altro, occorre che essi siano modellati e compresi, ed è qui che entra in gioco l’intelligenza artificiale di cui si dirà tra breve. I dati, però, devono innanzitutto essere trovati e, in una rete che ormai comprende oltre 10 miliardi di nodi e che contiene Zettabyte di dati (testi, immagini, misure, ecc.), trovare l’informazione che si cerca è un processo complesso. La rete è quindi continuamente esplorata e mappata dai grandi motori di ricerca che indicizzano e classificano le informazioni in essa contenute. Farlo richiede infrastrutture di calcolo enormi in grado di immagazzinare quantità inimmaginabili di dati e di elaborarli in tempo reale. Solo i BDP sono in grado di farlo, proprio perché il controllo dei dati stessi ha dato loro le indispensabili risorse economiche, e questo ha comportato una centralizzazione dell’informazione che non ha uguali nella storia dell’umanità. Ma questa è solo parte dell’intera storia. Intorno al 2001, i BDP si accorsero infatti che i loro centri di calcolo erano utilizzati al massimo per il 20% del tempo e iniziarono ad affittare il restante 80% dell’infrastruttura, dapprima in termini di “storage” e quasi immediatamente dopo anche in termini di potenza di calcolo. Nacque così il paradigma del “cloud computing” che, malgrado la sua natura “distribuita”, incorpora in modo indissolubile una concezione centralizzata della società e che è il cuore della cosiddetta “infosfera”. Ciò ha fatto sì che non solo il dato, ma l’intera infosfera (dati +i algoritmi + infrastrutture di calcolo) sia controllata dai BDP assicurando agli stessi BDP il monopolio di un mercato pressoché illimitato. Poiché lo scopo dei BDP è innanzitutto il profitto non ci si può poi scandalizzare se chi paga per i loro servizi è un candidato o un partito durante una campagna elettorale, come nel recente caso della società Cambridge Analytica[12] coinvolta nelle elezioni di Trump negli USA.
Con un’indovinata metafora si può affermare che “l’informazione è il petrolio del XXI secolo”. Ciò ci pone dinanzi a scenari che richiedono a tutti un grande salto evolutivo. Il Web, come diceva il grande giurista Stefano Rodotà, senza una “costituzione” rischia di essere il Far West del XXI secolo[13]. Forse è arrivato il tempo di definire un’etica dei dati che assicuri «quell’habeas data che i tempi mutati esigono, diventando così, com’è avvenuto con l’habeas corpus, un elemento inscindibile dalla civiltà»[14]. La metafora di Rodotà è molto più calzante di quanto appaia a prima vista. Si sta infatti riproponendo quanto è già accaduto agli inizi del XX secolo con il progressivo ma rapidissimo affermarsi di un’economia fondata sul petrolio. Un inizio selvaggio, non controllato da una legislazione apposita, in cui pochi pionieri si contendevano le concessioni e i diritti di trivellazione, seguito da un progressivo accentramento dell’estrazione nelle mani di poche compagnie (le famigerate sette sorelle) e un perfezionamento della filiera che portava dal petrolio grezzo ai suoi derivati. Anche in quel caso, i governi si mossero tardi e solo quando era divenuto evidente che lo spostamento dei capitali e gli interessi economici erano tali da causare stravolgimenti a livello globale. Va però detto che la situazione attuale è molto più pericolosa a causa di due fattori che raramente vengono tenuti in conto: la mancanza di una o più ideologie in grado di fornire risposte a problemi globali e il fatto che l’informazione che potrebbe portare a eventuali prese di posizione contrarie è essa stessa controllata dai BDP. All’epoca del petrolio, l’affermazione di una nuova tecnologia era socialmente spendibile perché mentre da un lato si aveva la sparizione di posti di lavoro di basso livello, dall’altro se ne creavano – e in misura ancora maggiore – di nuovi. Ai minatori di carbone si sostituivano gli addetti alle trivelle, alle raffinerie i lavoratori della plastica e migliaia di nuovi posti di lavoro erano creati dall’indotto associato alla nuova tecnologia. La rivoluzione in corso oggi porterà invece alla sparizione di interi settori lavorativi creando solo un numero molto ridotto di nuovi lavori ad alto contenuto specialistico e tecnologico e quindi non sarà in grado di offrire soluzioni praticabili alle masse. È facile intuire quale potrà essere l’impatto sociale di una rivoluzione siffatta.
2. Machine learning, IA debole e BDA
Chi scrive è convinto che l’Intelligenza Artificiale (IA) debole sia etichettata come IA solo per motivi di marketing e che in realtà l’IA debole più che essere una vera e propria forma seppure elementare di IA, è solo un primo mattone da cui in un futuro non troppo lontano si potrà giungere all’attivazione di una IA forte, cioè dotata di autocoscienza. Va anche detto, però, che gli sviluppi dell’informatica in termini di capacità di immagazzinamento dei dati e di velocità di elaborazione, uniti a una sempre migliore comprensione dei meccanismi di funzionamento del cervello umano, fanno sì che l’Intelligenza Artificiale non sia più un argomento da lasciare alla fantascienza, ma una realtà che già oggi inizia a influenzare la vita di ognuno di noi. Si è già detto che i dati da soli non hanno molto significato. Le informazioni, invece, sono dati contestualizzati e interpretati, che quindi hanno un significato, «differenze che creano differenze»[15] e almeno in potenza, un profondo impatto su chi le riceve. Sin dagli albori dei Big Data fu chiaro che la contestualizzazione, classificazione e interpretazione dei dati non potevano essere effettuate con tecniche tradizionali e richiedevano la messa a punto di metodi automatici in grado di estrarre l’informazione velocemente e in modo accurato senza intervento di operatori umani. La prima fase dell’IA (finita tra il 2012 e il 2015) è quindi consistita nel mettere a punto strumenti in grado di compiere operazioni elementari su grandi volumi di dati. Con una selvaggia semplificazione si può riassumere queste tecniche sotto nomi familiari ai più: “Machine Learning” (apprendimento delle macchine) o “Statistical Learning” (apprendimento statistico). Unite alle tecniche avanzate di visualizzazione, queste discipline formano la cosiddetta “Big Data Analytics” o BDA. La necessità di sfruttare appieno i Big Data causò un improvviso ri-fiorire delle ricerche in queste discipline per applicazioni che spaziavano dall’astrofisica all’analisi dei mercati finanziari. Va però evidenziato che fino a quando queste tecniche sono applicate in un contesto problem driven (cioè sono dettati dalla necessità di risolvere uno specifico problema), non si può parlare di IA.
2.1 Brevissima introduzione al machine learning
Vale però la pena di soffermarsi un attimo sui due paradigmi fondamentali della BIg Data Analytics (o del Machine Learning). L’enorme arsenale di algoritmi (perché di questo e non altro si tratta) che è stato implementato in oltre mezzo secolo di ricerche (per alcuni esempi si veda la tabella), può essere diviso in base alle due principali modalità di utilizzo[16].
- modalità supervisionata (MS): l’algoritmo impara a effettuare una e una sola operazione addestrandosi su un insieme di dati per cui si conosce a priori la risposta desiderata (Base di Conoscenza).
- modalità non supervisionata (MnS): l’algoritmo raggruppa i dati in base a considerazioni statistiche applicate ai dati stessi e senza bisogno di conoscenza a priori.
Anche le tipiche operazioni di Machine Learning possono essere facilmente schematizzate in due tipi principali .
- Classificazione e regressione (CR). Partendo da una consistente base di conoscenza formata da esempi etichettati, ci cui cioè si conosce la risposta (target) a una data domanda, gli algoritmi devono imparare a predire la risposta per altri oggetti simili ma non etichettati (ad esempio potrebbe essere una raccolta di immagini di animali divise in gatti, cani, elefanti e altro). Una volta addestrato, il classificatore viene poi applicato su altre immagini non usate per l’addestramento. Se il target è una categoria (es. gatto, cane, leone, etc.) si parla di classificazione. Se invece il target è un valore numerico, si parla di regressione.
- Clustering (Cl). In questo caso, i dati vengono raggruppati in assenza di qualsiasi informazione a priori, in base alla loro maggiore o minore similitudine (definita da opportune metriche e indicatori statistici). Un numero ridotto di oggetti per cui si è in possesso di informazioni dettagliate può poi essere usato per capire ogni raggruppamento (o cluster) a che tipologia di oggetti corrisponde (fase di labeling).
Per effettuare queste operazioni esiste un gran numero di algoritmi che possono essere anche combinati tra loro in una varietà pressoché infinita (e questo è anche il motivo per cui spesso si parla di “art of Data Science”). Ogni algoritmo ha i suoi pregi e i suoi limiti e, soprattutto, non sempre può essere utilizzato in combinazione con altri algoritmi senza introdurre perniciosi errori nei risultati. Alcune ulteriori considerazioni sono necessarie per capire i limiti e i possibili errori causati da un cattivo uso della BDA.
- La quasi totalità degli algoritmi di ML sono molto sensibili all’incompletezza dei dati[17]. In altre parole, in un data set complesso è possibile che per alcuni oggetti (record) manchino alcune informazioni. Se i dati incompleti superano un certo limite, gli algoritmi divengono incapaci di apprendere la regola sottostante e forniscono risultati inaffidabili. Quanto più i dataset da utilizzare sono grandi e complessi, tanto più aumenta la loro incompletezza e quindi la possibilità che gli algoritmi conducano a risultati errati. Ovviamente questa limitazione è particolarmente importante per l’utilizzo dei Big Data.
- Impossibilità di estrapolare. Gli algoritmi di classificazione/regressione sono di fatto metodi di interpolazione e, in quanto tali, non sono adatti a estrapolare risultati al di fuori dei limiti di applicazione definiti dalla base di conoscenza su cui sono addestrati. In altre parole, se ad esempio sto addestrando il mio algoritmo a decidere qual è la terapia migliore per un dato tipo di paziente e la mia base di conoscenza è costituita da uomini e donne con età compresa tra i 12 e i 70 anni e con reddito medio alto, le previsioni per un uomo di 80 anni o per un trentenne di reddito basso possono essere (e quasi sempre lo sono) completamente errate.
- La maledizione della dimensionalità (curse of dimensionality). Al crescere del numero di parametri che caratterizzano un dato oggetto o evento, l’efficacia dell’addestramento diminuisce. Il perché è facile da capire facendo riferimento alla figura 1. Si supponga di avere una base di conoscenza formata da 1000 oggetti per ognuno dei quali si sa la risposta (target) e di cui sono stati misurati N parametri. Se voglio classificare usando solo 2 parametri i 1000 punti si distribuiranno in un piano, se uso tre parametri in uno spazio, se ne uso quattro in un ipervolume a 4 dimensioni, se ne uso 10 in un ipervolume a 10 dimensioni, e così via. A ogni parametro che si aggiunge la dimensionalità aumenta e la densità di punti di addestramento nell’ipervolume corrispondente diminuisce. In altre parole, se il numero di parametri cresce troppo, la densità degli esempi diviene troppo bassa per permettere un addestramento efficace e l’affidabilità dei risultati diminuisce.
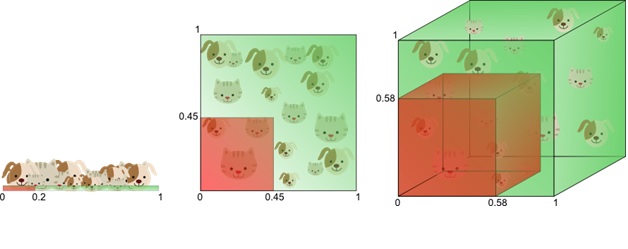
Figura 1: esemplificazione del “curse of dimensionality”
Ciò implica che un eccesso di misure può in alcuni casi risultare deleterio e condurre a risultati sbagliati. Infine, non si può fare a meno di menzionare il cosiddetto “overfitting”. In pratica, se non si usano particolari precauzioni, l’algoritmo può imparare a riprodurre in modo perfetto l’insieme di dati su cui è stato addestrato, ma risultare assolutamente inutile quando applicato a dati simili che non sono stati usati per il suo addestramento. In altri termini, l’algoritmo diviene bravissimo nel descrivere i dati su cui è stato addestrato, ma è incapace di generalizzare. Di fatto, occorre sempre trovare un compromesso (arbitrario) tra accuratezza e capacità di generalizzazione. In altre parole, le previsioni ottenute con i metodi di machine learning sono passibili di molti errori e, per usarle in modo efficace, occorre adottare una serie di precauzioni e avere piena coscienza dei possibili problemi. L’utente finale dovrebbe quindi essere (e quasi sempre non lo è) in grado di accedere oltre che alla previsione finale, anche a una serie di informazioni quali: le caratteristiche della base di conoscenza e i suoi limiti, la percentuale di dati incompleti e il tipo di algoritmo usato insieme alla sua maggiore o minore sensibilità all’incompletezza dei dati; il numero di parametri usati e i criteri in base ai quali essi sono stati selezionati, etc... In assenza di queste informazioni, l’utente finale non è in grado di valutare il rischio insito nelle previsioni che gli sono state fornite e deve per forza di cose delegare alle aziende di BDA e ai BDP la decisione sulla loro maggiore o minore affidabilità. Quindi l’avvento dell’era dei BDP, della BDA e dell’IA debole impone una maggiore diffusione di competenze tecniche specifiche che, al momento, sono appannaggio di pochi. Purtroppo, anche la scienza, come ogni altra attività del mondo moderno, risente delle mode e di una certa superficialità che induce molti a cimentarsi nella “Big Data Analytics” senza avere la preparazione necessaria. Basta scaricare dalla rete uno dei tanti pacchetti di programmi oppure usare un’applicazione on line[18] perché chiunque si senta in grado di fare i suoi esperimenti e avviare le sue analisi. Inutile dire che un approccio siffatto è quasi sempre fonte di disastri e ha, in un certo senso, contribuito a generare una sorta di sfiducia nelle applicazioni di IA debole all’interno della comunità scientifica.
2.1.1 La scelta dei parametri (feature selection)
Tutti gli algoritmi di machine learning scalano male (cioè il tempo di calcolo aumenta rapidamente) con il numero di dati da elaborare e, soprattutto, con il numero di parametri (o feature) che gli vengono dati in pasto. Per meglio comprendere ciò che si dirà in seguito, è necessario introdurre un ulteriore aspetto del problema, quello della cosiddetta Feature Selection (FS)[19]. La FS consiste nell’identificare le feature necessarie a risolvere un dato problema: un passo essenziale anche per cercare di minimizzare gli effetti del curse of dimensionality di cui si è già parlato. Anche in questo caso l’approccio non è univoco e si basa su compromessi più o meno arbitrari. Si può infatti desiderare di trovare un set minimo di feature al fine di minimizzare i tempi di calcolo senza perder troppo in termini di accuratezza; oppure si può voler trovare il gruppo di feature ottimale per raggiungere un dato livello di accuratezza, oppure si potrebbe voler determinare quello che contiene tutta l’informazione necessaria a risolvere un dato problema (all relevant FS). Un primo problema è che, al crescere del numero e dell’eterogeneità dei parametri aumenta la possibilità di trovare correlazioni spurie. Correlazioni simili a quelle scherzosamente riportate sul sito della tylervigen[20] , dove si scopre, ad esempio, che il numero di persone morte per affogamento in piscina ha una forte correlazione con il numero di film in cui ha recitato Nicholas Cage.
Infine occorre menzionare un altro aspetto: come si definisce la misura del successo di una data applicazione di ML o BDA? Quali metriche è opportuno adottare? Il problema non è solo statistico ma, in molti casi, come si spera di riuscire a dimostrare nei prossimi paragrafi, esso è anche e soprattutto un problema di scelte etiche.
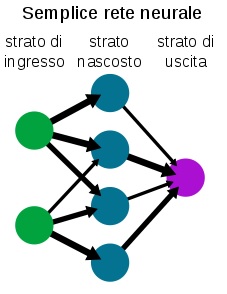
Figura 2: semplice schema di percettrone multi-strato
Anche così, comunque, si pongono problemi filosofici non banali e, almeno a conoscenza di chi scrive, poco trattati. Ad esempio, dall’utilizzo di questi metodi sta infatti emergendo un nuovo concetto di “verità”. Alla verità “deterministica” a cui siamo in un certo senso abituati, si sta infatti sostituendo una “verità statistica” basata su dati incompleti. Una sostituzione non solo di termini, ma concettuale, che ha implicazioni tutt’altro che banali sia sull’affidabilità della conoscenza che sui processi decisionali.
2.1.2 Il Percettrone multistrato
Il cuore di questa intelligenza di primo livello sono le cosiddette reti neurali. Una rete neurale[21] molto semplice (il cosiddetto Multi Layer Perceptron o MLP) può essere schematizzata come in Figura 2 ed è concettualmente quanto di più stupido e meno simile all’intelligenza si possa immaginare. Una rete è organizzata in strati di neuroni ed è direzionale, cioè l’informazione si sposta dallo strato dei neuroni di ingresso verso lo strato dei neuroni di uscita. Ogni nodo (chiamato neurone) è connesso con altri neuroni dello strato precedente (da cui riceve valori numerici) e di quello successivo (a cui passa valori numerici). La connessione avviene attraverso semplici funzioni matematiche che leggono i valori che arrivano al nodo dai neuroni dello strato precedente e ne ricavano un valore che viene passato ai neuroni a esso connessi nello strato successivo. E così via. Capire come una struttura siffatta possa apprendere in modalità supervisionata è facile. Supponiamo di dovere insegnare a una rete neurale a riconoscere in immagini prese a caso la presenza o meno di una o più bottiglie. Per farlo si ha bisogno di un archivio di fotografie “etichettate” in cui cioè un operatore umano ha riconosciuto la presenza o assenza delle bottiglie (la base di conoscenza di cui si è già parlato). A questo punto, dopo avere inizializzato a caso i valori numerici che arrivano ai neuroni (collegamenti), si danno le immagini in pasto alla rete. Per ogni immagine la rete fornirà una risposta (supponiamo che il 50% sia giusto). A questo punto si modificano lievemente i valori dei collegamenti e si ripete l’operazione, se la percentuale di successo migliora significa che sto modificando i collegamenti nella direzione giusta. Questa procedura viene reiterata molte volte fino a quando la rete non raggiunge il livello di accuratezza desiderato (cioè ad esempio, fornisce il risultato corretto nel 95% dei casi). A questo punto si congelano i valori dei collegamenti e si passano altre immagini (non etichettate) alla rete che nel 95% dei casi sarà in grado di riconoscere in modo corretto se esse contengono o no bottiglie. Sembra quasi impossibile che un algoritmo così semplice possa essere il cuore pulsante della rivoluzione in corso, eppure è così.
2.2 Il secondo livello dell’IA debole
Già nel 1997, l’IA di Deep Blue di IBM ha battuto gli esseri umani nel gioco degli scacchi. Nel 2011 un altro computer dell’IBM, Watson, ha vinto il quiz televisivo Jeopardy. Nel 2012 un computer che faceva uso di quel deep learning di cui si dirà tra breve ha imparato da solo a riconoscere il concetto di gatto e a separare le immagini di teste di gatto e di esseri umani. Nel maggio del 2017 il programma AlphaGo della Deep Mind (società controllata da Google) ha battuto il campione del mondo del gioco più complesso mai ideato, il cinese Go. Altri algoritmi di IA presiedono al funzionamento delle auto a guida automatica, dell’atterraggio e del decollo degli aerei e, in alcuni casi, controllano strumentazione così complessa che senza di essi l’Uomo non saprebbe nemmeno dove iniziare. Dal 2015, analisi oncologiche complesse che richiederebbero decenni a medici in carne e ossa, vengono svolte in minuti da algoritmi di IA in grado di sfruttare le informazioni contenute nei Big Data. Certo, si tratta ancora di una IA limitata ma, di certo, enormemente più potente di quella del primo livello.

Figura 3: Portrait of Edmond Belamy. Il primo dipinto realizzato da un IA di terzo livello
Questa nuova generazione di IA è nata in pochi anni (meno di un decennio) dalla combinazione di “Big Data” e una tecnica neurale nota da tempo ma riscoperta, potenziata e rinominata da Google “Deep Learning” o “apprendimento profondo”: una serie di algoritmi in grado di scoprire pattern e regolarità in miliardi e miliardi di dati (soprattutto immagini)[22]. Un apprendimento che può essere sia guidato (supervised) che autonomo (unsupervised). In pratica una rete di deep learning altro non è che una concatenazione di reti neurali tradizionali che riconoscono una gerarchia di fattori comuni ai dati su cui vengono addestrate. A ogni strato della sequenza le caratteristiche riconosciute acquisiscono un grado sempre maggiore di generalità. Ovviamente, anche in questo caso, esistono molte diverse possibilità sia nella scelta degli algoritmi che nella loro modalità di combinazione. Le reti di Deep Learning di Google, per imparare da sole il concetto di gatto, hanno processato per alcuni giorni alcune decine di milioni di immagini estratte da youtube e dai suoi archivi. Come spesso accade, gli entusiasti di questa nuova tecnologia promettono meraviglie ma è già chiaro che il Deep Learning è solo il primo dei numerosi passi che occorrerà fare per passare all’IA forte: quella dotata di autocoscienza. Mentre l’IA debole (quella di primo e secondo livello) non si è ancora sottratta al controllo dei suoi creatori, l’IA forte deciderà da sola di quali problemi occuparsi e in che modo. Le reti di Deep Learning sono oggi utilizzate per moltissime applicazioni tra cui anche la guida automatica. Occorre però ricordare che l’addestramento delle reti di Deep learning risente di tutti i problemi fin qui elencati con l’unica differenza che, data la loro maggiore complessità, diviene ancora più difficile tenere sotto controllo tutti i fattori che possono influenzare l’accuratezza dei risultati. Se una rete di questo tipo sbaglia una previsione e, ad esempio, causa la morte accidentale di una persona quando questa viene investita da una macchina a guida neurale, come si fa a capire cosa è andato storto? Le telecamere hanno sicuramente visto la sagoma della persona ma non l’hanno riconosciuta come tale. Il problema è perché? Come si fa a capire cosa ha visto una rete di Deep Learning?

Figura 4: immagini classificate da Google Deep Dream con un’accuratezza del 99%
Per cercare di rispondere a questa domanda, Google applica un metodo relativamente semplice che consiste nell’invertire il processo e chiedere a una rete di DL addestrata di rispondere a una specifica domanda. Ad esempio: “Che cosa è per te un pavone?”. A questo punto si genera un’immagine casuale e poi la si perturba un po’ alla volta iterando fino a quando la rete non la classifica come pavone. Ovviamente il processo conduce a risultati spesso surreali (o che almeno appaiono tali a un’intelligenza umana). Ritorniamo per un attimo al meccanismo di funzionamento: la rete vede nell’immagine una gerarchia di componenti che va dai piccoli dettagli fino alla visione d’insieme. Ad esempio, al primo livello rileva linee curve, che poi fa convergere nel riconoscimento di un occhio che poi riconosce come parte di un volto. Certo, quelle linee curve potrebbero essere parte di oggetti molto diversi quali, ad esempio una barca. Ma se la rete è addestrata correttamente, queste interpretazioni vengono scartate nei livelli successivi (una barca non si può trovare in un volto). Si veda, ad esempio la figura 4 che mostra come una rete di Deep Learning classifica immagini all’apparenza incomprensibili. Viene naturale chiedersi perché la seconda immagine della seconda fila oppure la terza dell’ultima vengano classificate come “pavone”. È ovvio però che in questo processo di ottimizzazione, la convergenza verso lo stato finale avviene molto lentamente e, quindi, lungo la strada, la rete segue un andamento abbastanza imprevedibile. Se le fornisco l’immagine di un albero e le dico che si tratta di un edificio, il processo di adattamento cercherà di far emergere strutture a forma di edificio all’interno dell’immagine (Figura 5). Questo meccanismo è alla base del metodo che Google ha immaginificamente chiamato (per motivi di marketing) Deep Dream[23].

Figura 5: applicazione di Google Deep dream all’immagine di un albero

Figura 6: una tipica immagine prodotta dalle reti di Google Dreams
Verrebbe da chiedersi cosa ha a che fare tutto ciò con i meccanismi della visione umana. Molto di più di quanto non sembri a prima vista e per convincersene basterà ricordare i dettami della “Similarity Gestalt” che studiano la ben nota attitudine che il cervello umano ha a riconoscere forme specifiche in oggetti che con quella forma non hanno nulla a che fare: forme di animali nelle nuvole, volti umani nelle rocce, ecc. Il cervello, di fatto, opera almeno per quanto concerne la visione come una rete di Deep Learning molto, molto profonda. Come vedremo nei paragrafi successivi, un grave problema etico si pone già oggi, con l’AI debole, dove molti programmi si auto-scrivono e imparano da soli come gestire problemi complessi trovando spesso soluzioni a priori imprevedibili.
2.2.1 Spazio dei parametri, complessità e AI di secondo livello
Il fatto che l’IA debole non possa in alcun modo essere assimilata a una forma di intelligenza non vuol però dire che essa non consenta di superare molti limiti dell’intelligenza umana. Un aspetto in cui già ora l’IA debole mostra di essere molto più efficace del cervello umano è la capacità di trattare dati complessi. Iniziamo con il ricordare che Il cervello umano è il risultato di millenni di evoluzione, in cui si è adattato – in un certo senso ottimizzato – a reagire a stimoli sensoriali che provengono dal mondo tridimensionale con cui interagisce. Ciò è particolarmente vero per la vista che, proprio per la complessità dei processi a essa associati, ha richiesto un’ottimizzazione particolarmente accurata. Tale adattamento introduce un forte “bias” (l’italiano “effetto di selezione” non rende altrettanto bene l’idea) nella capacità di identificare forme, correlazioni e strutture in spazi con dimensionalità maggiore di 3. Ciò mentre da un lato porta a una ipersemplificazione della nostra descrizione scientifica del mondo di cui si dirà in seguito, dall’altro fa sì che la Big Data Analytics surclassi il cervello umano nell’analisi di fenomeni complessi. Da un punto di vista matematico, si può dire che ogni evento o “record” di un data base definisce un punto in uno spazio a N dimensioni, dove N è il numero di parametri indipendenti misurati (Spazio dei Parametri o SP) ed è un numero molto grande, dell’ordine delle parecchie centinaia o di alcune migliaia. Il riconoscimento dell’esistenza di una possibile correlazione tra parametri avviene attraverso l’identificazione di strutture (es. linee, piani, etc.) in uno spazio definito dai parametri stessi. I nostri occhi e il nostro cervello non consentono di rivelare tali strutture in più di tre dimensioni. Come si è già detto, soprattutto quando si ha a che fare con spazi dei parametri molto complessi, la scoperta di correlazioni tra due o tre variabili induce spesso a conclusioni errate. Anche quando la correlazione viene dimostrata reale e in fenomeni più complessi, la dipendenza da un eventuale quarto parametro appare come un discostamento dei punti misurati dalla struttura definita dai tre parametri identificati come principali[24]. I computer e la BDA, non risentono di questi bias e offrono la possibilità di superare i limiti posti alla conoscenza dal nostro stesso cervello e di identificare pattern che legano anche tutte e N le variabili. In altre parole, possono scoprire correlazioni tra m variabili con m molto, molto maggiore di 3 e, quindi, aprire la strada al riconoscimento di leggi empiriche ordini di grandezza più complesse di quelle che attualmente conosciamo.
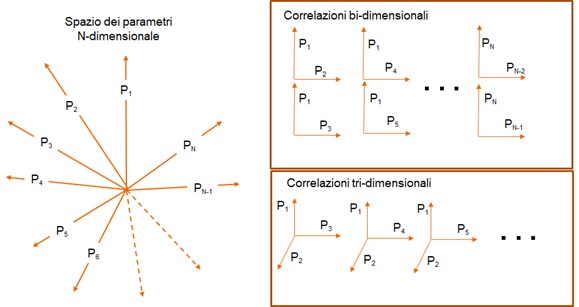
Figura 7: schematizzazione di uno spazio dei parametri N-dimensionale. A destra in alto: frammentazione dello SP in tutte le possibili combinazioni usate per la ricerca di correlazioni tra due parametri. In basso a destra: le possibili combinazioni usate per la ricerca di correlazioni tra tre variabili, etc...
L’impatto positivo che questa possibilità ha sulla scienza presente e futura verrà discussa nel Capitolo 4. Occorre anche soffermarsi sul fatto che una cosa è riconoscere l’esistenza di correlazioni N-dimensionali e un’altra è rendere tali correlazioni intelligibili all’Uomo. Ed è qui che entra in gioco un capitolo importante della Data Science, la cosiddetta “data visualization”, che nelle sue implementazioni più semplici (in genere usate per applicazioni finanziarie) consiste nel proiettare in diagrammi bidimensionali le informazioni più rilevanti ma che trova la sua vera dimensione in applicazioni molto più complesse, su cui si tornerà in seguito. Un ulteriore problema strettamente correlato a ciò di cui si è appena parlato, è quello della feature selection, cioè dell’identificazione del set di parametri più adatto a risolvere un dato problema. Anche qui, ci si muove in una zona di ambiguità e si debbono operare delle scelte.
3. Il volto cattivo di Giano
Google Dream emula la visione umana, IA di terzo livello hanno prodotto i primi dipinti in modo autonomo. Altre ancora, stanno – anche in questo momento – componendo brani musicali originali. Le AI deboli di terzo livello hanno cioè iniziato a creare. E questo deve far riflettere. Tutte le rivoluzioni del passato hanno infatti riguardato l’homo faber, cioè la capacità del genere umano di creare manufatti per meglio controllare un ambiente potenzialmente ostile. La rivoluzione in corso riguarda invece l’homo sapiens, cioè non la capacità di fare, ma la capacità di pensare e creare. Alla luce di questa semplice considerazione e di quanto si è detto nei paragrafi precedenti appare quantomeno preoccupante che il dibattito etico/legale al momento sembri occuparsi quasi esclusivamente dei problemi posti dalla tutela della privacy. Questo è certamente un problema importante che investe i diritti del cittadino e delle aziende (e in ultima analisi degli stati) e si articola in varie sfumature: dalla tutela della privacy all’estrema difficoltà di rendere i dati anonimi[25]. In Richards e King si fa notare che in un’epoca in cui i BD e la BDA influenzano pressoché ogni aspetto della vita del cittadino sia in modo diretto (dalla ricerca di un partner o un’abitazione, agli acquisti, alle cure mediche, alle votazioni politiche, ecc) che indiretto (controllo ambientale e del territorio, prevenzione del terrorismo, ecc.) è sorprendente che gli individui non abbiano la minima idea di quali dati vengano raccolti, del come essi vengono raccolti e ancor meno del come essi vengano distribuiti e condivisi tra le aziende[26]. Gli autori ritengono che l’unico modo per sottrarre l’individuo a questa forma di controllo sulle loro vite e quella di sviluppare una solida teoria etica dei Big Data e costringere gli stati a implementarla. Una teoria etica che deve disciplinare anche aspetti solo all’apparenza secondari quali il fatto che i BDP possono decidere (e di fatto lo fanno) di usare i dati raccolti per scopi diversi da quelli per cui erano stati raccolti (riutilizzo delle informazioni), e la possibilità che i dipendenti dei BDP abbiano accesso a informazioni (accesso non autorizzato) riservate che di fatto non dovrebbero vedere[27]. Ad esempio, in mancanza di specifiche precauzioni e procedure, anche se uno specifico database è reso anonimo, la sua combinazione con altri dataset effettuata da un BDP, può trovare correlazioni che rimuovono tale anonimità. Nunan e Di Domenico hanno analizzato in dettaglio questa possibilità definendola “paradosso dell’uso non intenzionale”[28]. Tra i tanti esempi da loro presentati, particolarmente istruttivo è il lavoro di alcuni ricercatori che, usando informazioni e fotografie estratte da Facebook in combinazione con un software per il riconoscimento facciale sono riusciti a collegare i profili facebook a molti profili anonimi pubblicati su un sito di appuntamenti on-line. Infine, almeno al momento, gli stati si rivolgono agli stessi BDP per trovare soluzioni a problemi che da soli non sanno affrontare. Si veda, ad esempio, il problema del Data Masking (che impedisce il riconoscimento del proprietario dei dati), la cui migliore risoluzione al momento è fornita utilizzando strumenti creati dall’IBM. Ma quello della privacy è solo la punta dell’iceberg. Ancor più gravi appaiono però i rischi legati a un uso spregiudicato o troppo semplicistico della BDA[29]. Tra questi: l’influenza negativa che essa può avere sui comportamenti e sulle decisioni delle aziende, il fatto che le decisioni prese sono necessariamente inaccurate, sia per l’incompletezza dei dati che per l’inadeguatezza dei modelli matematici usati. Senza entrare nel dettaglio, per iniziare, ci si soffermerà su uno di questi aspetti. Si supponga che una ditta produttrice di aeroplani usi la BDA per stabilire se un dato aeromobile debba o no essere soggetto a revisione e che usi come parametro l’ottimizzazione dei costi di gestione. Un risparmio di alcune centinaia di milioni di euro può valere un rischio maggiore per le vite dei passeggeri? La risposta ovvia e no, ma pur facendo salva la buona fede delle ditte, come si può essere certi che gli algoritmi preposti al controllo e i dati usati per l’analisi non contengano errori che portano a decisioni sbagliate? Come si può essere certi del fatto che un certo committente non chieda ai BDP di fornirgli informazioni per operazioni potenzialmente pericolose, illegali o poco etiche? Inoltre: i Big Data sono permanenti. Si supponga che un BDP utilizzi anche dati di un’epoca in cui esistevano discriminazioni di qualsivoglia tipo (per razza, sesso o orientamenti religiosi e sessuali). Questi dati saranno certamente contaminati da pregiudizi, bias legati a una certa epoca e un certo orientamento politico. Come si può essere certi che la presenza di questo sottoinsieme di dati all’interno di un dataset più grande non condizioni i risultati della BDA?
3.1 Necessità di una nuova legislazione
Quanto detto porta naturalmente all’altro aspetto della vicenda: le implicazioni legali. Gli aspetti legali legati all’uso dei Big Data sono potenzialmente dirompenti ed eppure i legislatori sembrano ignorarli. Di nuovo, per chiarire la complessità del problema è opportuno fare un esempio. Supponiamo che in un paese esistano leggi che proteggono il cittadino contro le discriminazioni (sesso, razza e religione) e che un cittadino qualsiasi chieda un prestito a una banca o un posto di lavoro a un ente e che questo ente si rivolga a un BDP per decidere sull’affidabilità del candidato. Anche se la banca o l’azienda non forniscono le suddette informazioni, il BDP di turno può inferirle dalla scia elettronica del candidato e decidere, ad esempio, che una donna giovane non è adatta a occupare una certa posizione in quanto è molto probabile che debba prima o poi assentarsi per maternità, o che un uomo che vive in un quartiere con bassi indici economici abbia meno probabilità di restituire un prestito. Data l’impossibilità di accedere al dettaglio delle motivazioni della decisione, (la matrice di pesi della rete neurale preposta al compito non può essere tradotta in una serie di regole decifrabili) il cittadino non avrebbe neppure la possibilità di avviare un procedimento legale per difendere i propri diritti.
Un altro grave problema che si profila all’orizzonte dei legislatori è legato alla sparizione di molte vecchie professioni, all’apparizione di nuovi lavori e alla completa disarticolazione del mercato del lavoro. Già oggi, molti degli operatori dell’economia digitale e dei Big Data si collocano in una regione indefinita tra i salariati di tipo tradizionale e i prestatori d’opera a tempo determinato. La trasformazione di un servizio pre-esistente attraverso nuove forme di comunicazione e supporto digitale (la cosiddetta “uberizzazione del lavoro”) crea spesso apparenti zone di ambiguità e di perdita di diritti da parte del lavoratore e del consumatore a vantaggio dei fornitori di servizio. Vale però la pena di sottolineare come ciò sia dovuto più a una scarsa comprensione da parte del legislatore della natura intrinseca del lavoro digitale più che a una reale vacanza legislativa (al riguardo si legga l’interessante articolo di Consiglio[30]).
Non si può, inoltre, non menzionare il problema posto dalla cosiddetta e-discovery in ambito legale. Un aspetto attualmente molto dibattuto nella legislazione statunitense[31], ma ancora pressoché inesistente in quella europea e in quella italiana. In un mondo digitale, la documentazione legale che documenta l’attività di grandi aziende, Banche o enti, consiste spesso di centinaia di migliaia se non milioni di documenti digitalizzati. Il reperimento dell’informazione utile a un certo procedimento legale è di fatto impossibile con tecniche tradizionali e occorre ricorrere alla Big Data Analytics e, in particolare, al predictive coding[32]. Tali tecniche consentono di identificare rapidamente i documenti necessari ma non forniscono una misura di errore e, soprattutto, non assicurano che tutta la documentazione relativa al caso sia stata prodotta. La decisione del tribunale viene così a essere influenzata da informazioni incomplete. Anche in Italia, l’autorità giudiziaria può ricorrere a indagini effettuate con Troiani inseriti nei dispositivi dell’indagato e così facendo vengono quasi sempre raccolti dati che non hanno nulla a che fare con il reato per cui si indaga, dati che peraltro, rimangono negli archivi digitali in modo permanente. È inutile sottolineare come tutto ciò comporti una violazione dei diritti dell’indagato.
Infine, la Big Data Analytics sta rivoluzionando anche il concetto stesso di proprietà intellettuale rendendone pressoché impossibile non solo la tutela, ma persino la sua definizione. Come sottolineato da Richard e King, la BDA renderà presto obsoleto il concetto stesso di brevetto dato che la quantità di dati disponibili nei BDP renderà praticamente impossibile la ricerca della cosiddetta “prior art” e la definizione del grado di originalità di una proposta.
Occorrerebbe far comprendere ai legislatori che nell’infosfera, nello scenario on-life, dove i confini tra reale a virtuale si confondono, l’identità digitale va rispettata come un’estensione della persona, che ha sempre una sua dignità e autonomia che vanno rispettate. Se però si leggono le varie proposte di soluzioni non può non sorprendere il fatto che il legislatore, si occupi di ciò che dovrebbero o non dovrebbero fare le “organizzazioni”, mai di cosa dovrebbero e potrebbero fare gli stati. Inoltre, il legislatore, molto spesso agisce in mancanza di quelle competenze tecniche che appaiono indispensabile per decidere in un ambito così complesso. Se a ciò si aggiunge il fatto che la rete e i BDP sono di fatto internazionali e che esistono profonde differenze nelle legislazioni di stati diversi, il quadro diviene ancor più preoccupante. Per esempio, al momento esistono non pochi problemi riguardanti lo scambio di Big Data tra Europa e Stati Uniti. In questi ultimi, una varietà di leggi proteggono solo alcuni aspetti legati alla salute e alle transazioni finanziarie, mentre in Europa le leggi sono molto più restrittive[33].
I Big Data pongono quindi un problema quasi insormontabili all’Etica Kantiana che, fondandosi sul rispetto dell’autonomia e dei diritti delle persone, mal si concilia con i BDP che sistematicamente raccolgono informazioni sulle persone senza il loro diretto consenso e usano tali informazioni non per il bene delle persone ma a fini di profitto. Si potrebbe obbiettare che, in molti casi, le aziende che contribuiscono ai BDP chiedono il consenso al trattamento dei dati personali ma, di fatto, la complessità dei Big Data è tale che nessun individuo è in grado di controllare ed eventualmente rimuovere la propria “scia elettronica”. Al più si possono utilizzare servizi che permettono di controllare eventuali furti di identità digitale, oppure frodi bancarie oppure di sapere quando il proprio nome appare in post o in altre forme. Di fatto si ha a che fare con un controllo retroattivo effettuato solo dopo che “il danno” è già stato fatto. Ancor più sottile è il fatto che questa scia elettronica indirettamente definisce e condiziona la volontà di uno specifico individuo senza il suo consenso. Di ciò si ha una chiara evidenza nella radicalizzazione delle idee politiche, delle teorie dei catastrofisti o di quelle antiscientifiche, che è una diretta conseguenza del connubio tra social networks e BD. Se credo nell’idea A (anche se A è alquanto balzana, ad esempio nell’efficacia curativa dei Fiori di Bach) basteranno un paio di visite a siti dove si parla di A per far sì che A diventi uno degli elementi della mia scia elettronica e, quindi, i browser e i vari siti WEB che si rivolgono ai BDP per aumentare i loro clienti, faranno uso di questa informazione e mi proporranno solo siti o articoli che sono legati ad A, al fine di compiacermi. Altrettanto complesso, se non addirittura impraticabile, è cercare di valutare i Big Data nell’ambito delle teorie utilitaristiche. I pro e i contro dei Big Data dovrebbero infatti essere pesati su una stessa scala al fine di capire se i pro dominano sui contro o viceversa. E questo dovrebbe essere fatto sia nel caso dei singoli individui che in quello della società nel suo complesso[34].
3.2 Armi di distruzione matematica
Nel suo eccellente libro Cathy O’Neil ha introdotto il termine “Weapons of Math Destruction”[35] e mette in evidenza come la Big Data Analytics possa essere usata per prendere decisioni non solo sbagliate ma addirittura dannose[36]. Vale la pena di citare un suo esempio tratto da un contesto, quello della valutazione delle prestazioni dei docenti, che appare particolarmente importante nell’attuale contesto, dove una sorta di indicatori mai abbastanza criticati viene usata dal legislatore per giudicare la qualità della ricerca e le politiche di reclutamento degli atenei italiani.
Negli USA, gli amministratori pubblici usano una serie di indicatori per valutare le capacità e le prestazioni dei docenti delle scuole di ogni ordine e grado e se un docente non raggiunge un certo “score”, può ricevere sanzioni di vario tipo che contemplano anche il licenziamento. Ma come si può valutare un insegnante? Uno degli insegnanti era considerata estremamente brava sia dai suoi superiori che dai genitori dei suoi allievi. Eppure venne licenziata. Dopo un giusto ricorso la colpa venne attribuita all’algoritmo utilizzato da Mathematica Policy Research, la ditta di Princeton a cui era stata commissionata l’indagine. La ragione del suo basso punteggio era che, secondo l’algoritmo, alcuni dei suoi studenti avevano mostrato un significativo peggioramento al termine dell’anno scolastico. Tale peggioramento, però era attribuibile a molte altre cause che nulla avevano a che fare con le prestazioni dell’insegnante: i genitori di un alunno si erano separati, un altro studente era stato vittima di bullismo, un altro ancora aveva un malato terminale nella sua famiglia. In un campione piccolo, come è quello formato dai venti-venticinque studenti di una classe, le fluttuazioni statistiche e gli eventi straordinari giocano un ruolo importante, soprattutto quando lo si confronta con medie ottenute analizzando decine se non centinaia di migliaia di casi. Soprattutto, in molte applicazioni commerciali[37] dei Big Data non è previsto il “feedback”, cioè una correzione retroattiva indotta dalla valutazione dei risultati stessi. Di esempi analoghi a quelli discussi dalla O’Neil ne esistono centinaia. Tra questi esempi negativi va senz’altro incluso l’operato dell’ANVUR (Agenzia Nazionale di Valutazione dell’Università e della Ricerca) che utilizza una serie di metodi e indicatori statistici assolutamente inadatta a descrivere la complessità del problema per condizionare profondamente la vita culturale e le politiche di reclutamento degli atenei italiani[38]. Eppure, con i suoi algoritmi errati, l’ANVUR condiziona la crescita culturale degli atenei italiani e l’attività degli enti di ricerca più di quanto sia mai accaduto in passato. Ma questi sono problemi di oggi, relativamente semplici e a cui, con un po’ di buona volontà e una migliore comprensione della complessità, si potrebbe porre rimedio. Non si può fare a meno di chiedersi cosa accadrà nel prossimo futuro, quando decisioni sempre più complesse verranno prese da AI del terzo livello, cioè quando la complessità dei dati e degli algoritmi sarà tale da non potere essere compresa e controllata da un essere umano. In questo caso diverrebbe difficile persino attribuire in modo preciso la responsabilità di una cattiva decisione. Ad esempio, se lo scopo ultimo fosse quello di trovare una strategia per massimizzare il ritorno economico di un’azienda e se la strategia proposta dagli algoritmi comportasse una riduzione nelle misure di sicurezza che poi causa incidenti sul lavoro, di chi sarà la colpa? dell’azienda? Della ditta a cui l’azienda avrà “outsourced” la data analytics? Del BDP che avrà fornito i dati incompleti? Cosa accadrebbe se un datore di lavoro effettuasse le proprie selezioni di personale da assumere utilizzando algoritmi sbagliati o incompleti? Per fare un esempio banale: la grande maggioranza degli operatori di borsa è di razza bianca e ha un’età compresa tra i 26 e i 36 anni. Un algoritmo basato su queste statistiche potrebbe portare una ditta a operare una discriminazione razziale senza averne la consapevolezza. Se ciò accadesse, di chi sarebbe la colpa? Secondo stime delle Gartner, nel momento in cui i BD sono utilizzati per processi decisionali e funzioni complesse, essi conducono inevitabilmente a violazioni etiche e di privacy, al punto che – si stima – già nel 2019 circa il 50% delle violazioni etiche nel mercato finanziario saranno riconducibili a un uso improprio della Big data Analytics[39]. Non sorprende che molti ritengano che sia arrivato il tempo di una “responsible research and innovation”, ovvero di una educazione per le giovani generazioni di tecnologi e di ingegneri che prepari non solo persone esperte e appassionate di innovazione ma anche persone consapevoli dello spaventoso impatto sociale che le tecnologie dell’informazione hanno su tutti noi e sulla democrazia. L’introduzione di una data ethics-by-design (allo stesso modo della privacy by design) nel percorso di formazione di tutti i professionisti del mondo ICT diventa sempre più urgente. Non a caso, anche in Italia si iniziano ad avere corsi di computer ethics nelle scuole di ingegneria (al Politecnico di Torino dal 2008, al Politecnico di Milano dal 2016 e nell’Università di Napoli a partire dal 2019). Recentemente, la Corte Europea di Giustizia[40] ha stabilito il diritto del cittadino a ottenere la cancellazione dei dati da qualunque BDP soggetto alla normativa. Un contrasto evidente con quanto invece accade negli Stati Uniti dove tale legislazione è invece assente[41]. Anche dall’altro lato dell’oceano qualcosa ha comunque iniziato a muoversi nell’ambito di compagnie ed enti privati, pur se in modo molto marginale. Si veda ad esempio la Future of Computing Academy avviata all’interno della statunitense ACM per migliorare il livello di consapevolezza etico e il senso di responsabilità sociale delle prossime generazioni di “Computer Scientists”. Il 17 luglio, la FCA ha pubblicato un proprio codice etico legato al processo di peer review degli articoli scientifici pubblicati dai propri membri o sulle proprie riviste. In pratica il referee dovrebbero verificare oltre che l’originalità del lavoro anche il fatto che le possibili implicazioni negative del lavoro siano esposte con chiarezza. Un’iniziativa di certo lodevole ma sulla cui efficacia è lecito avere seri dubbi. In pratica equivale a dire che una ricerca su, ad esempio, una nuova arma biologica, purché originale verrebbe pubblicata a patto che venisse chiaramente ammesso che l’uso di quell’arma potrebbe causare uno sterminio di massa. Inoltre, poiché come si è detto la maggior parte della ricerca nel settore dei Big Data e dell’IA si svolge all’interno dei giganti dell’informatica che hanno un forte interesse a mantenere riservati i risultati della loro ricerca, è chiaro che misure del genere avrebbero poca o nessuna efficacia.
- Il volto buono di Giano
Without data you’re just another person with an opinion.
Edwards Deming
Alla luce di quanto detto in precedenza, verrebbe da chiedersi perché non si intervenga in modo drastico, ponendo fine una volta per tutte alle ricerche e agli sviluppi in questo settore. Basterebbero le sole considerazioni economiche per rendersi conto dell’impossibilità di farlo. Come si è detto, infatti, l’intera economia del terzo millennio si fonda o fa uso della rivoluzione in corso. Ma ci sono anche altri motivi. Se ben usati, Big Data e A.I. possono effettivamente condurre l’uomo alla soglia di quel mondo ideale ipotizzato dai filosofi transumanisti. Una cura definitiva per la maggior parte delle malattie attualmente incurabili, un potenziamento delle capacità cerebrali dell’uomo e delle sue potenzialità fisiche, un prolungamento della vita attiva, una maggiore libertà nella gestione del proprio lavoro e del tempo libero, la possibilità di compiere viaggi interplanetari e forse anche interstellari. Per ognuna di queste possibilità straordinarie sono stati scritti interi volumi e non avrebbe senso soffermarsi su di esse. Per una breve sintesi si consiglia il sito Transhumanism[42]. In quanto segue ci si soffermerà, invece, su un aspetto spesso ignorato: le straordinarie possibilità che si aprono per il futuro delle scienze di base.
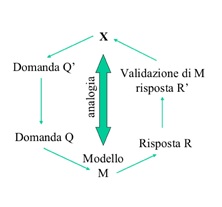
Figura 8. Schematizzazione del metodo scientifico secondo Toraldo di Francia [Toraldo di Francia 1976]
4.1 Un nuovo livello di complessità nella conoscenza: “la scienza della Scienza”
In anni recenti si è diffuso un nuovo termine “scienza della Scienza” [Rency] che riassume un insieme di considerazioni su come la rivoluzione in corso possa influenzare il progresso delle conoscenze scientifiche. Purtroppo, come spesso accade, soprattutto in questa nuova era dominata dal “publish or perish” in cui molti ricercatori non si danno il tempo di leggere letteratura specializzata più vecchia di tre anni, il termine “scienza della Scienza” è solo una nuova etichetta che non si capisce bene dove si distingua dalla vecchia “epistemologia”. Ma, si sa, un buon modo per conquistarsi una nicchia in un ambiente molto competitivo è quello di ignorare ciò che è stato fatto prima e affibbiare nuove etichette a concetti antichi. Le leggi di natura, sono derivate da leggi empiriche formulate a partire da misure e dal riconoscimento che alcune grandezze sono correlate tra loro. Nella maggior parte dei casi, la formulazione matematica della legge avviene solo dopo tale riconoscimento. Per capire meglio ciò che sta accadendo conviene innanzitutto riassumere brevemente e in modo ipersemplificato una possibile definizione del cosiddetto metodo scientifico che sovrintende la prassi della ricerca in pressoché tutti i settori. In pratica si tratta di un’iterazione su una serie di passi standard. Secondo Toraldo di Francia[43] e seguendo lo schema in Figura 8, si parte da:
- attenta osservazione di un fenomeno naturale X;
- in base a tali osservazioni si formula una domanda Q’;
- si acquisisce l’insieme di conoscenze accumulate fino a quel momento su quello stesso fenomeno;
- si formula un modello o un esperimento M;
- si trasforma la domanda Q’ in una domanda Q per il modello M;
- si ottiene una risposta R valida per il modello e,
- si trasforma questa risposta R in una risposta R’ da confrontare con il fenomeno X.
- Se la risposta non soddisfa, si reitera la procedura.
Il risultato viene poi valutato dalla comunità scientifica attraverso il ben noto processo di “peer review”. L’avvento dei Big Data e della Big Data Analytics sta cambiando tutti i vari passi del processo. Nel linguaggio attuale, i passi da 1 a 3 corrispondono alla cosiddetta exploratory analysis. Si parte da una base di dati e si rivela un pattern o una correlazione che debbono essere interpretati. Il passo [4] implica nella maggior parte dei casi la progettazione di una simulazione numerica in grado di rappresentare il fenomeno e, dopo avere trasformato la domanda iniziale in una domanda per i dati prodotti dalla simulazione [punto 5], si ottiene una risposta dai dati simulati [6] che poi si trasforma in una risposta per la domanda iniziale [7]. I Big Data, il calcolo distribuito e la BDA consentono di accelerare tutte queste fasi accedendo on-line a tutti i dati[44] e a tutta la letteratura rilevante, permettendo la realizzazione di simulazioni complesse che forniscono risposte complesse che senza le tecniche di IA debole non potrebbero essere comprese e confrontate con i dati reali. Anche la ricerca di strutture nei dati simulati e il loro confronto con i dati reali può in molti casi essere effettuato solo con le tecniche della BDA. Ma se fosse solo questo, si tratterebbe solo di un cambiamento importante ma quantitativo. In realtà, le possibilità offerte dai Big Data e dalla BDA aprono la strada a una scienza molto più complessa di quella attuale.
4.1.1 Il passo zero del metodo scientifico
Il primo passo dell’elenco precedente prevede l’attenta osservazione “di un fenomeno X”. Ma cosa è un fenomeno? È facile accorgersi che a nostra descrizione del mondo si basa su fenomeni descritti da leggi che prevedono al più tre variabili indipendenti: la legge di gravità, quella dei gas perfetti, l’evoluzione stellare, etc... sono tutte descritte in base a due, massimo tre variabili. Solo in alcuni casi, si ricorre a un quarto parametro che però viene in genere considerato una sorta di effetto del secondo ordine della legge principale. È naturale quindi chiedersi se questa relativa semplicità del mondo fisico che conosciamo sia una manifestazione del fatto che, in fondo, l’universo è molto più semplice di quanto non si pensi o, piuttosto, se non si tratti di un bias, di un effetto di selezione introdotto dall’Uomo nella sua descrizione del mondo. Prendiamo il caso dell’astrofisica e della cosmologia[45] dove l’avvento della tecnologia dei Big Data ha consentito di fare enormi passi avanti e di fondare addirittura nuovi domini di indagine. Una vera e propria rivoluzione che trova le sue basi nella cosiddetta Astroinformatics: una nuova disciplina che si pone all’intersezione di statistica, matematica, astronomia e informatica[46]. La cosmologia studia le proprietà dell’universo cercando di comprendere le proprietà individuali e collettive dei mattoni costituenti dell’Universo: le galassie. I moderni strumenti di osservazione consentono di ottenere informazioni accurate su grandi campioni di galassie[47]. I Big Data e l’IA debole intervengono a ogni stadio di questo processo. Algoritmi di machine learning sono preposti al coordinamento delle osservazioni, alla ripulitura dei dati dagli effetti strumentali, alla misurazione dei parametri (luminosità apparente, raggio, forma, concentrazione della luce, etc). Altri ancora (in genere vari tipi di reti neurali e di deep learning) sono utilizzati per derivare quantità fisiche fondamentali quali distanza, massa, tasso di formazione stellare, ecc.
Il primo immediato vantaggio è nel fatto che grazie a questo nuovo approccio è possibile ottenere informazioni per un numero estremamente grande di oggetti. Cosa che sarebbe stata pressoché impossibile con approcci più tradizionali. Ma questa è solo la parte meno interessante e rivoluzionaria della vicenda. Il secondo aspetto è che, grazie alle tecnologie dei Big Data è possibile fondere informazioni ottenute per uno stesso oggetto celeste con strumenti diversi (satelliti nel dominio dei raggi X e Ultravioletto, telescopi per il vicino infrarosso, satelliti per il lontano infrarosso e radiotelescopi operanti a diverse frequenze) e ottenere quindi una visione completa o pancromatica dell’Universo. Questo permette di affrontare problemi che in passato erano assolutamente impossibili. Inoltre, l’avvento di nuovi strumenti in grado di osservare ripetutamente la stessa porzione di cielo, consente di studiare in gran dettaglio come le proprietà di alcuni tipi di oggetti variano nel tempo. Si è così aperto un nuovo campo di ricerca, la Time Domain Astronomy[48] che promette di essere uno dei settori più proficui della ricerca del prossimo ventennio. Anche la recente scoperta delle onde gravitazionali avrebbe avuto una rilevanza minore se non fosse stato per la possibilità di esplorare gli enormi archivi astronomici alla ricerca di eventi che si erano verificati in cielo nello stesso istante in cui erano stati rivelati i segnali gravitazionali (astronomia multimessenger). Questi primi due aspetti sono stati resi possibili da un enorme sforzo internazionale[49] finalizzato innanzitutto alla fusione e interoperabilità di tutti i database astronomici esistenti nel mondo. Un’operazione grandemente facilitata dal fatto che i dati astronomici sono sia intrinsecamente privi di valore economico (non possono essere usati per generare profitto), sia (dopo un breve periodo proprietario[50]) pubblici.
Tra le altre cose, l’astronomia è stata anche la prima a esplorare una nuova forma di IA ibrida che coniuga l’IA di primo e secondo livello con l’intelligenza naturale e così facendo ha anche dato l’avvio alla cosiddetta “citizen science” [CS] che coinvolge nel processo di ricerca grandi comunità di appassionati. Il primo di questi progetti fu il “Galaxy Zoo”[51] che usò una platea di quasi trecentomila privati cittadini distribuiti in tutto il pianeta per classificare on-line le forme di oltre un milione di galassie (Intelligenza naturale). I risultati di tale classificazione furono poi omogeneizzati e analizzati utilizzando l’IA debole. L’utilizzo di tali tecniche è ormai talmente diffuso che in molti casi i ricercatori non si accorgono nemmeno di usarle (direttamente o indirettamente) e farne a meno risulterebbe ormai impossibile, a meno di non volere rinunciare a risolvere alcuni dei problemi più interessanti. Ma questo è il presente. Per capire le potenzialità dell’AI debole nell’immediato futuro occorre fare una breve digressione. La fusione dei dati raccolti da strumenti diversi e in epoche diverse fa sì che la “scia digitale” di un oggetto celeste sia estremamente complessa (fotometria a diverse lunghezze d’onda e in diverse epoche, morfologia, spettroscopia, modelli teorici, articoli pubblicati, ecc.). In altre parole, nell’ultimo decennio, lo spazio dei parametri astronomici è esploso e ciò significa che, per la prima volta nella storia, sta diventando possibile esplorare la possibile esistenza di leggi fisiche più complesse. I primi risultati di questo nuovo approccio sono molto promettenti.
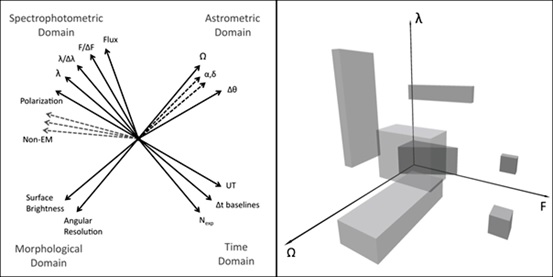
Figura 9: schematizzazione dello spazio dei parametri N-dimensionale delle osservazioni astronomiche. A destra una proiezione schematica dello stesso spazio su tre assi. I parallelepipedi esemplificano come apparirebbero le regioni dello spazio coperte da osservazioni
Ad esempio, in Figura 10, si mostra come un’operazione relativamente semplice (l’identificazione di candidati quasar[52] all’interno di un catalogo di oggetti costituito prevalentemente da stelle) possa essere grandemente migliorata usando spazi di parametri di dimensioni crescenti.
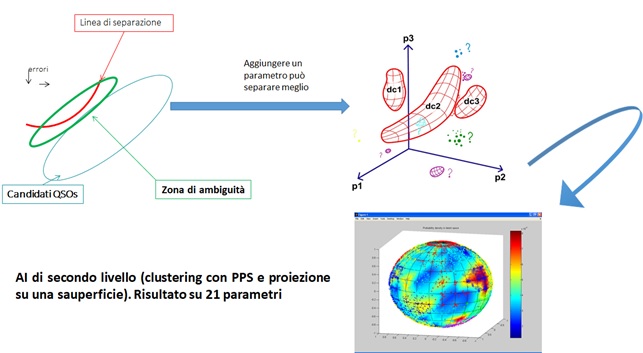
Figura 10: un esempio di come l’estensione dello spazio dei parametri possa migliorare la comprensione di un fenomeno. In passato, la ricerca di quasar a partire da dati nel visibile avveniva confrontandone i colori (cioè il rapporto di flussi ottenuti a lunghezze d’onda diverse) con quello degli altri oggetti. Un’operazione esemplificata nel diagramma in alto a sinistra. Con tale approccio, le stelle normali formano la nube di punti neri a sinistra della linea rossa, mentre i quasar si collocano all’interno della regione ellittica disegnata in azzurro. A causa degli errori di misura e delle caratteristiche intrinseche esiste una regione di oggetti ambigui (ellisse verde). Aggiungere una terza dimensione (diagramma in alto a destra) consente di separare meglio gli oggetti in quanto rimuove la degenerazione dovuta alla proiezione su uno dei piani cartesiani. La figura in basso mostra invece la separazione che si ottiene utilizzando uno spazio dei parametri a 21 dimensioni e un algoritmo di clustering. La distribuzione di punti si frammenta in una serie di nuvolette di punti con caratteristiche diverse
4.2. La Data Driven Discovery
Nel 2003 il cosmologo e filosofo della scienza Martin Harwit[53] scrisse un saggio a mio parere fondamentale, in cui riprendeva le idee già presentate nel libro Cosmic Discovery[54]. In esso, Harwit analizza le scoperte astronomiche degli ultimi due millenni[55] per evidenziare il rapporto tra innovazione tecnologica e progresso delle conoscenze. Di fatto, in astronomia come in pressoché tutte le scienze, l’introduzione di una nuova tecnologia quasi sempre produce risultati inaspettati.
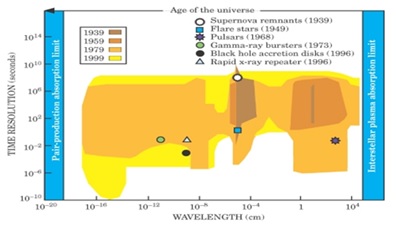
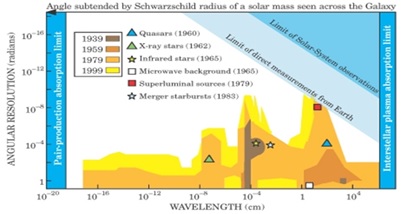
Figura 11: due diagrammi estratti dal saggio di Harwit in cui si mostrano due proiezioni bidimensionali dello Spazio dei Parametri astronomico
In Figura 11, ad esempio, si mostrano due proiezioni bidimensionali del PS astronomico (risoluzione angolare verso lunghezza d’onda e risoluzione temporale verso lunghezza d’onda). Le zone di diverso colore corrispondono a epoche diverse definite in base all’introduzione di nuove tecnologie quali, ad esempio, l’introduzione di satelliti in grado di osservare l’universo a lunghezze d’onda corrispondenti ai raggi X, ecc. I simboli di varia forma e colore presenti in entrambi i casi marcano, invece, le scoperte astronomiche più importanti dello scorso secolo. Come si può vedere, tali scoperte si collocano quasi sempre in prossimità di zone di transizione. Cioè esse sono avvenute sempre in corrispondenza di periodi in cui erano avvenuti significativi miglioramenti nella nostra capacità di ampliare, campionare o correlare lo Spazio dei Parametri. In altre parole, secondo la chiave interpretativa proposta da Harwit, per capire in che direzione andare in futuro occorre trovare le regioni del PS che non sono coperte da osservazioni, oppure che lo sono ma sono campionate in modo incompleto o irregolare. Nel caso dell’astronomia – ma il discorso trova una diretta eco in quanto sta accadendo in molte se non tutte le discipline scientifiche – la chiave per effettuare nuove scoperte è nei Big Data. Infatti, negli ultimi decenni, il progresso tecnologico ha fatto sì che gli strumenti di misura abbiano raggiunto in molti settori il limite fisico e che il progresso della conoscenza non sia più legato esclusivamente alle sole tecnologie hardware (strumenti, sensori, etc.) ma anche alla nostra capacità di estrarre informazione utile dallo Spazio dei Parametri astronomico utilizzando la BDA. Nel caso dell’astrofisica, i rivelatori coprono ormai tutte le lunghezze d’onda, hanno un’efficienza di rivelazione prossima al 100%, (tutti i fotoni vengono raccolti e misurati), una grande risoluzione angolare e spettrale. Detto in altre parole, non è pensabile che nei prossimi decenni sviluppi significativi si possano avere dall’apertura di nuove finestre osservative (cioè dall’introduzione di nuove dimensioni nello spazio dei parametri). L’astrofisica è entrata a pieno titolo nell’era della cosiddetta Data Driven Discovery che, già da qualche anno, inizia a essere massicciamente applicata anche al di fuori dell’ambito strettamente scientifico. In pratica, la BDA mostra chiaramente che, in molti casi, il costringere le macchine a emulare i processi del cervello umano conduce a risultati decisamente peggiori di quando, invece, le si lascia interpretare i dati in modo autonomo. “Let the data speak for themselves” (“lasciare che i dati parlino da soli”) è il paradigma fondante di questa nuova metodologia ed è un paradigma che, per certi versi, spinge alle sue estreme conseguenze la Feature Selection di cui si è parlato in precedenza. Di nuovo, per capire meglio di cosa si parla, è opportuno fare un esempio. Un problema ricorrente, che da oltre un decennio è affrontato con tecnologie di BDA, è quello dei cosiddetti “photometric redshift”: cioè la misurazione delle distanze (redshift) delle galassie usando dati fotometrici multibanda (cioè ottenuti attraverso filtri che coprono diversi intervalli di lunghezze d’onda). Su questo problema, alcune decine di gruppi, hanno sperimentato le più svariate tecniche di BDA utilizzando dati eterogenei. Senza voler entrare nel dettaglio dell’enorme letteratura esistente[56], ci si fermerà su due risultati estremamente interessanti che possono aiutare a capire la differenza tra FS traditionale, DDD e la rilevanza di quest’ultima. Occorre innanzitutto specificare che l’accuratezza dei risultati in questo tipo di esperimenti è generalmente espressa in termini di “media” e di “deviazione standard”[57]. Con riferimento alla figura 12, il pannello in alto a destra mostra il risultato finale ottenuto da Laurino et al. facendo uso dei dati della Sloan Digital Sky Survey[58] [SDSS]. Per ogni punto del grafico, in ascissa è riportato la stima spettroscopica del redshift (molto accurata) e in ordinata la stima fotometrica ottenuta usando tecniche di Machine Learning (meno accurata ma basata sui soli dati fotometrici). In questo lavoro, i dati dati in pasto alla rete neurale che stimava i redshift fotometrici erano flussi misurati in cinque diversi intervalli di lunghezze d’onda scelti – tra gli oltre 330 parametri forniti dalla SDSS – utilizzando la “wisdom of the experts”, cioè l’esperienza di esperti del settore. Kai Polsterer dello ITHS di Heidelberg[59] ha affrontato lo stesso problema utilizzando gli stessi dati ma con un approccio data driven. Invece di scegliere a priori quali parametri utilizzare lanciò oltre quattrocentomila esperimenti utilizzando di volta in volta una diversa combinazione di cinque parametri scelti a caso tra i 55 più significativi (sempre secondo la Wisdom of the experts) tra quelli forniti dalla SDSS. I risultati sono mostrati nel pannello in alto a destra della Figura 12. In questo grafico, ogni punto rappresenta i risultati di un esperimento espressi in termini di media e deviazione standard. La stella blu marca la posizione dell’esperimento corrispondente a Laurino et al. Come si può facilmente evincere, i risultati ottenuti usando l’approccio tradizionale sono molto peggiori di quelli ottenuti dal migliore esperimento fatto senza scelte a priori, in base alle proprietà dei dati (stella verde). Infine, nel diagramma in basso si mostra ciò che accade se, invece di limitare il numero di parametri utilizzati a cinque si lasciano i programmi di machine learning liberi di trovare il numero e la combinazione di parametri ottimale. Come si vede, le macchine trovano che i risultati si stabilizzano utilizzando almeno dieci parametri opportunamente scelti.
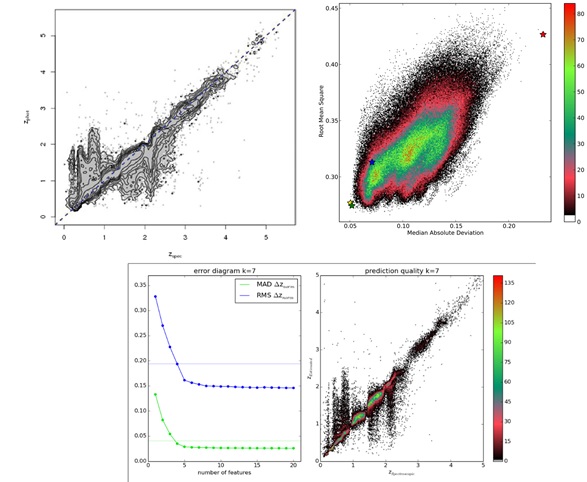
Figura 12: In alto a sinistra (dal lavoro di Laurino et al.) risultati della predizione di redshift fotometrici ottenuti utilizzando cinque parametri fotometrici. In alto a destra il risultato del lavoro di Polsterer et al. ottenuti effettuando esperimenti su tutte le combinazioni 5 a cinque estratte da un sottoinsieme di 55 parametri estratti dalla SDSS (per i simboli si veda il testo). In basso a sinistra i risultati in termini di numero di parametri dove si nota chiaramente la stabilizzazione dei risultati quando si raggiungono i 10 parametri
In entrambi i casi, si trova che i parametri utilizzati negli esperimenti migliori (cioè quelli che forniscono media e deviazione standard più piccoli) non solo non avrebbero mai potuto essere scelti da un esperto ma che addirittura non hanno alcun senso per un astronomo. In altre parole, nel lavoro di Polsterer si mostra che l’approccio tradizionale basato sulla misurazione e utilizzo di parametri definiti dall’utente e misurati in base a procedure “model driven” non consente di catturare tutta la complessità dei dati e che, se ci si affida alle scelte operate da esperti in base alla loro esperienza, si ottengono risultati meno accurati e precisi di quelli che le macchine sono in grado di ottenere da sole. In questo caso si ha un esempio di risultati scientifici prodotti dalle macchine in piena autonomia e senza nessun ricorso a un’esperienza umana definita a priori. Va rilevato che, data l’impossibilità di trasformare le matrici di pesi delle reti, l’operato delle macchine è – anche in linea di principio e non solo in pratica – incomprensibile per l’utente. Occorre fidarsi.
5. Conclusioni
I Big Data e la Big Data Analytics sono qui per restare. Ed è giusto che sia così, visti gli enormi vantaggi che essi producono e ancor più produrranno in medicina, sostenibilità, ecologia, mercato e finanza, analisi sociale e scienze di base e applicate. Fermarli oltre che impossibile in pratica sarebbe sbagliato anche in teoria. Il problema è che gli uomini e le donne di questo millennio debbono imporre ai governi e ai legislatori di adottare politiche atte a disciplinarne l’uso e a porre stretti vincoli al loro utilizzo da parte di aziende, banche, enti pubblici e privati. I Big Data e la Big Data Analytics sono e ancor più saranno una forza dirompente nella vita privata di ciascuno di noi, nella vita delle aziende e dei governi, nella società nel suo complesso. Da essi dipenderanno i flussi di informazione e le decisioni che prenderemo in base a tali informazioni. per questa ragione I Big data e la Big Data Analytics non sono solo un problema di algoritmi e non possono essere lasciati nelle mani dei soli tecnici, siano essi matematici, data scientists o data analysts. Da quanto sin qui detto appare evidente che, in futuro, tra le cognizioni di base indispensabili per assicurare che un cittadino operi delle scelte consapevoli e, soprattutto per metterlo in condizione di difendersi dagli inevitabili abusi, sarà necessario inserire rudimenti di data science e di etica dei dati in ogni corso di studi. L’ignoranza di queste cognizioni di base è infatti un lusso che nessuna società civile può permettersi di correre. La democrazia, le libertà individuali, la privacy, la nostra stessa identità dipendono da ciò. Purtroppo, però, questa rivoluzione si sta verificando in un periodo storico in cui il livello di consapevolezza e partecipazione sociale è fortemente diminuito, così come il livello di istruzione e, soprattutto, di alfabetizzazione scientifica. Riuscire a vincere questa sfida non è più un’opzione da implementare in un futuro lontano, ma una necessità urgente.
Ringraziamenti
L’autore desidera ringraziare l’Avv. Barbara Cremona per le utili discussioni sui social e per avergli fornito alcuni riferimenti bibliografici sugli aspetti legali della Big Data Analytics; Rossella Consiglio e Annamaria Passaro per gli utili commenti sul manoscritto; George Djorgovski del California Institute Technology per le innumerevoli discussioni avute nel corso di oltre venti anni su vari aspetti della Data Science; Kai Polsterer dello Institute for Theoretical Studies di Heidelberg per le informazioni sulla Data Driven Discovery; Guglielmo Tamburrini per avergli fatto conoscere il problema delle “Weapons of Math Destruction”. Infine un ringraziamento particolare va ai colleghi Massimo Brescia e Stefano Cavuoti per avere condiviso per ben oltre un decennio con l’autore, il lavoro quotidiano e uno stesso percorso di crescita culturale. Senza di loro nulla di quanto scritto sarebbe potuto esistere.
[1] Cfr. P. Greco, I. Picardi, Hiroshima, la fisica riconosce il peccato: storia degli uomini che hanno inventato la bomba e degli uomini che hanno cercato di disinventarla, Nuova iniziativa editoriale, Milano 2005.
[2] Cfr. L. Alexandre, La Guerra delle Intelligenze: Intelligenza artificiale contro intelligenza umana, EDT, Torino 2018.
[3] 1 Zettabyte corrisponde circa a 1000 ettabyte, un milione di esabyte, un miliardo di Petabyte mille miliardi di Terabyte. Cioè, con buona approssimazione, 1 Zettabyte corrisponde alla capacità di archiviazione di 1000 miliardi di hard disk tipici.
[4] Cfr. S. Greengard, The Internet of Things, The MIT Press Essential Knowledge Series, Cambridge 2015.
[5] Cfr. IBM The Four V’s of Big Data (2016) https://www.ibmbigdatahub.com/infographic/four-vs-big-data
[6] Definita in termini di eterogeneità dei dati (Es. immagini, tabelle, testo, filmati, note scritte a mano).
[7] Numero di parametri misurati per ogni oggetto presente nei dati.
[8] Il valore di questa soglia dipende, di volta in volta, dalle prestazioni dell’hardware disponibile in una data epoca.
[9]https://techcrunch.com/2018/03/29/france-wants-to-become-an-artificial-intelligence-hub/?guccounter=1
[10] Cyber-utopisti: corrente di pensiero che vede nella tecnologia lo strumento per realizzare una società ideale in cui le leggi, il governo, e le condizioni sociali operino esclusivamente per il bene di tutti i suoi cittadini. Al riguardo si veda ad esempio F. Rampini, Rete padrona: Amazon, Apple, Google & Co., Feltrinelli, Milano 2014.
[11] E. Morozov, L’Ingenuità della rete: il lato oscuro della libertà di internet, Codice Edizioni, Torino 2011, p. 13.
[12] https://www.theguardian.com/news/series/cambridge-analytica-files
[13] Cfr. S. Rodotà, Una carta dei diritti del Web, Repubblica, 20 Novembre 2007.
[14] S. Rodotà, Privacy, libertà, dignità, Discorso conclusivo della Conferenza internazionale sulla protezione dei dati, Wroclaw, 14-16 Settembre 2004.
[15] Cfr. G. Bateson, Verso un’ecologia della Mente, Adelphi, Milano 1972.
[16] C. M. Bishop, Neural Networks for pattern recognition, Oxford University Press, 1996.
[17] Ibid.
[18] Brescia et al. xxxx, DAME.
[19] Cfr. I. Guyon, S. Gunn, M. Nikravesh & L.A. Zadeh Ed., Feature Extraction: Foundations and applications, Springer, Berlin 2006.
[20] http://www.tylervigen.com/spurious-correlations
[21] Checché ne dicano i colleghi d’oltre manica e d’oltre oceano il concetto moderno di rete neurale si deve al fisico italiano Eduardo Caianiello che nel 1961 nel suo lavoro introdusse la prima rete neurale in grado di operare su dati spazio-temporali; Cfr. E. Caianiello, Outline of a theory of thought processes and thinking machines, «Journal of Theoretical Biology», 2, 1961, pp. 204-235.
[22] N. Buduma, Fundamentals of Deep Learning, O’Reilly Inc., Massachusetts 2017.
[23] https://deepdreamgenerator.com/ creato da Alexander Mordvintsev, ingegnere di Google.
[24] Ad esempio, le proprietà osservate delle stelle sono comprese in termini di tre variabili indipendenti: temperatura, gravità superficiale e composizione chimica. Altri parametri quali ad esempio l’intensità del campo magnetico, il momento angolare, etc. vengono considerati alla stregua di effetti del secondo ordine.
[25] R. Herald, 10 Big Data Privacy Problems (2016).
[26] N.M. Richards, J.H. King, Big data ethics, in «Wake For. Law Rev.», 49, 2014, pp. 393-432.
[27] Cfr. M.J. Culhan, C.C. Williams, How ethics can enhance organizational privacy: lessons from the Choicepoint and TJX data breaches, «MIS Q.», 33, 4, 2009, pp. 673-687.
[28] Cfr. D. Nunan, M. Di Domenico, Market research and the ethics of big data, «Int. J. Mark. Res.», 55, 4, 2013, pp. 505-520.
[29] Cfr. N.M. Richards, J.H. King, Big data ethics, cit.
[30] «...sebbene il campione del digital labour intermediato dalle app si presti a essere colto, senza banalizzazioni, solo in tutta la sua complessità e articolazione, in Uber si riscontrano peculiarità tali da permettere l’emersione del prototipo cui si attribuisce sovente la funzione di declino dell’organizzazione fordista del lavoro e l’obsolescenza della relazione di lavoro classica. Allo stesso tempo è in virtù proprio delle qualità precipue di quest’app, della sua organizzazione e del suo stesso funzionamento che il prototipo del lavoratore sulla suddetta piattaforma Uber si presta a esser qualificato nel dominio di un rapporto di lavoro subordinato. L’interrogativo su cosa sia e cosa rappresenti l’uberizzazione del mercato del lavoro è stato posto al centro di molti studi della dottrina circa l’innovazione o meno delle relazioni industriali intessute dall’app, la natura dei rapporti in essere e la tipicità dei contratti. «Uber trasforma due forme di beni sottoutilizzati in capitale produttivo: una fonte di profitto. In tal modo, introduce una forma di concorrenza in un tipico settore dei servizi non negoziabile e fortemente regolamentato». Considerare Uber, quindi, come un servizio innovativo non è del tutto corretto poiché il servizio consiste nel trasportare una persona in un luogo predeterminato mediante una forma commerciale già esistente; Cfr. A. Consiglio, Il lavoro nella digital economy, prospettive su una subordinazione inedita, in «Labour and Law Issues», 4, 1, 2018.
[31] S. C. Bennett, E. Discovery, Reasonable search, proportionality, cooperation and advancing Technology, in «J. Marshall Journal Info Tech. & Privacy», L433 2014.
[32] N. Kogo, C. Trengove, Is predictive coding theory articulated enough to be testable?, in «Frontiers in Computational Neuroscience», 9, 111, 2015.
[33] R. Herschel e V. M. Mioei, Ethics and Big Data, in «Technology and Society», 49, 2017, pp.31-36
https://www.sciencedirect.com/science/article/pii/S0160791X16301373#bib20
[34] Cfr. M. J. Quinn, Ethics for the Information Age, Pearson, Hoboken, New Jersey 2017.
[35] Cfr. C. O’Neil, Weapons of Math Destruction, Crown Publ. co., Usa 2016.
[36] Cfr. A. Zoldan, More Data, More Problems: Is Big Data Always Right? (2016). http://www.wired.com/insights/2013/05/more-data-more-problems-is-big-data-always-right/.
[37] Feedback che invece è prassi normale nella statistica degli small data.
[38] Cfr. D. Borrelli, Contro l’ideologia della valutazione. L’Anvur e l’arte della rottamazione dell’università, Jouvence Editore, Milano 2015.
[39] Gartner on the future of Big Data analytics and cognitive computing, 2016. https://whatsthebigdata.com/2016/01/09/iia-forrester-idc-and-gartner-on-the-future-of-big-data-analytics-and-cognitive-computing/
[40] N. Terry, Navigating the Incoherence of Big Data Reform Proposals, 2014 Public Health Law Conference: Intersection of Law, Policy and Prevention, Spring (2015), pp. 44-47.
[41] Malgrado il fatto che la US Federal Trade Commission abbia più volte sostenuto la necessità di un consenso a priori necessario prima che il BDP raccolga i dati di un cittadino.
[42] https://whatistranshumanism.org/
[43] Cfr. G. Toraldo di Francia, L’indagine del Mondo Fisico, Einaudi, Torino 1976.
[44] Come spesso accade si tende a esagerare. Oggi, in molti casi vengono raccolti dataset specifici per l’analisi esplorativa dei dati che sono di gran lunga ridondanti. Ad esempio, [M15], hanno mostrato che meno dell’1% dei dati raccolti da una trivella di perforazione con circa 30.000 sensori ha una qualsivoglia utilità. Il resto è sostanzialmente inutile.
[45] Tale scelta è da un lato condizionata dall’esperienza lavorativa dell’autore e, dall’altro, trova una sua giustificazione nel fatto che l’astrofisica – proprio per il fatto di fondarsi su osservazioni e non su esperimenti – è stata la prima disciplina a doversi confrontare con il problema della Data Driven Science di cui si dirà a breve. Si vuole però sottolineare che considerazioni affatto simili si potrebbero fare per qualsiasi altro settore di indagine scientifica.
[46] M. Brescia et al., DAME (DAta Mining & Exploration).
[47] Si prenda ad esempio la Sloan Digital Sky Survey [SDSS] he fornisce informazioni per oltre 300 milioni di galassie e altrettante stelle. La SDSS è un po’ archetipo dei grandi database scientifici (oltre 12.000 lavori sono stati ricavati da essa) ed è diventata uno standard di riferimento per la cosiddetta Big Data Science.
[48] Cfr. E. Bernardini, Astronomy in the Time Domain, Science, 331, pp. 686-687, 2011.
[49] Oltre 27 progetti nazionali coordinati dalla International Virtual Observatory Alliance che ha visto la partecipazione di oltre 500 ricercatori per oltre 10 anni [IVOA].
[50] Per un periodo variabile tra sei mesi e un anno i dati grezzi sono riservati all’utilizzo solo da parte di chi li ha acquisiti. Dopo tale periodo vengono resi disponibili alla comunità. Anche tale approccio sta però cambiando in seguito al fatto che il volume di dati prodotto dai moderni strumenti e rivelatori è talmente grande da rendere praticamente inutile il periodo di accesso limitato.
[51] Galaxy zoo site: https://www.zooniverse.org/projects/zookeeper/galaxy-zoo/
[52] Quasar: oggetti cosmologici tra i più luminosi dell’universo. In realtà si tratta di una galassia al cui centro si annida un buco nero supermassiccio che accresce materia dall’ambiente circostante e ne converte parte in enormi quantità di energia. A causa della loro grande distanza, se osservate con normali telescopi ottici, risultano indistinguibili dalle normali stelle.
[53] Cfr. M. Harwit, The Growth of Astrophysical Understanding, in «Physics Today», 2003, pp. 38-44.
[54] Cfr. M. Harwit, Cosmic DIscovery, Harvester Press Brighton UK 1981.
[55] Cfr. M. Harwit, The Growth of Astrophysical Understanding, cit.
[56] Al riguardo si vedano: Brescia, M., Cavuoti, S. & Longo, G. Automated physical classification in the SDSS DR10. A catalogue of candidate quasars, in «Mon. Not. R. Astron. Soc.», 450, 2015, pp. 3893–3903; M. Salvato, O. Ilbert, B. Hoyle, The many flavours of photometric redshifts, Nature Astronomy, doi/10.1038/s41550-018-0478-0, 2018 e O. Laurino, R. D’Abrusco, G. Longo, G. Riccio, Astroinformatics of galaxies and quasars: a new general method for photometric redshifts estimation, in «Mon. Not. R. Astron. Soc.», 418, 2011, pp. 2165–2195.
[57] Per “media” si intende il valore medio (calcolato su tutti gli oggetti) della differenza tra il valore spettroscopico e quello fotometrico; per deviazione standard si intende la dispersione media dei punti intorno alla retta marcata in figura.
[58] La Sloan Digital Sky Survey è stata la prima grande survey digitale del cielo e ha marcato l’avvento della BDA in ambito scientifico. Con oltre 15.000 lavori pubblicati e oltre 200.000 citazioni può essere considerata uno degli esperimenti scientifici di maggiore successo.
[59] L. Gieseke, K. Polsterer, 2012, Photometric Redshift Estimation of Quasars: Local versus Global Regression, in Astronomical Data Analysis Software and Systems XXI, «Astron. Soc. of Pacific Conference Series», 461, 2012, a cura di P. Ballester, D. Egret, and N.P.F. Lorente, p. 537.





